

2025年2月28日-3月4日,第39届美国人工智能年会(AAAI 2025)在美国宾夕法尼亚州费城召开。实验室博士生孙玮琳、硕士生杨一萌、闫晓硕参加会议,并汇报展示论文成果。实验室共四篇论文被会议收录,其中一篇入选oral展示,三篇入选Poster展示:
1.论文题目:Hierarchically-Structured Open-Vocabulary Indoor Scene Synthesis with Pre-trained Large Language Model(AAAI 2025)
论文作者:Weilin Sun, Xinran Li, Manyi Li*, Kai Xu*, Xiangxu Meng, Lei Meng*
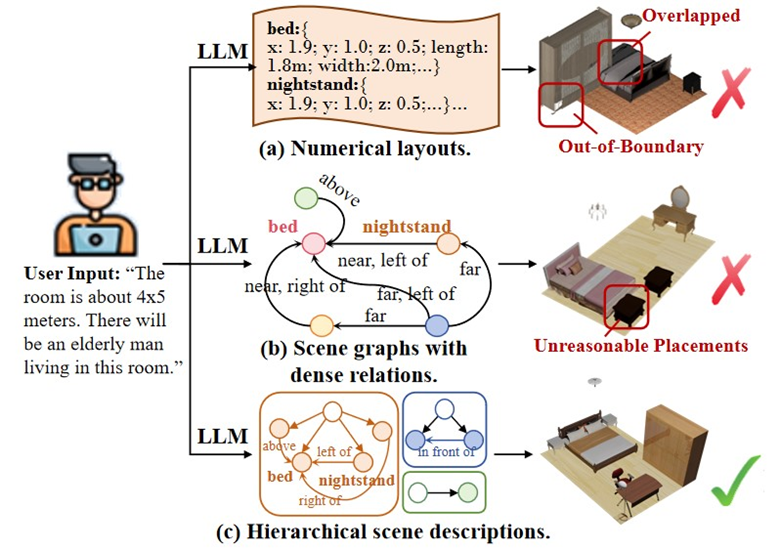
论文概述:室内场景合成技术致力于自动生成既合乎逻辑又逼真的三维室内环境,尤其强调满足用户的个性化需求。近年来,预训练的大型语言模型(LLM)在室内场景合成领域展现出了惊人的泛化能力。然而,将LLM生成的文本描述转化为既合理又符合物理规律的场景布局,仍是当前面临的一大挑战。在本文中,我们提出了一种新的方法,该方法首先利用LLM生成结构化的场景描述。随后,我们设计了一个结构感知与优化算法根据场景描述推断物体之间的空间关系,同时解决场景布局问题。我们从定性和定量两个方面进行了广泛的实验,以验证关键设计的有效性。实验结果表明,该方法能够生成更合理的场景布局,同时更好地满足用户需求和LLM描述。此外,我们还展示了开放词汇场景合成和交互式场景设计的结果,以体现该方法在实际应用中的优势。
2.论文题目:Curriculum Conditioned Diffusion for Multimodal Recommendation(AAAI 2025)(Oral, 600/3032)
论文作者:Yimeng Yang, Haokai Ma, Lei Meng*, Shuo Xu, Ruobing Xie, Xiangxu Meng
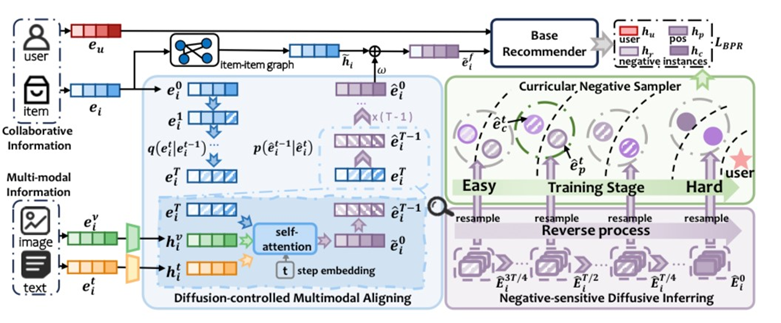
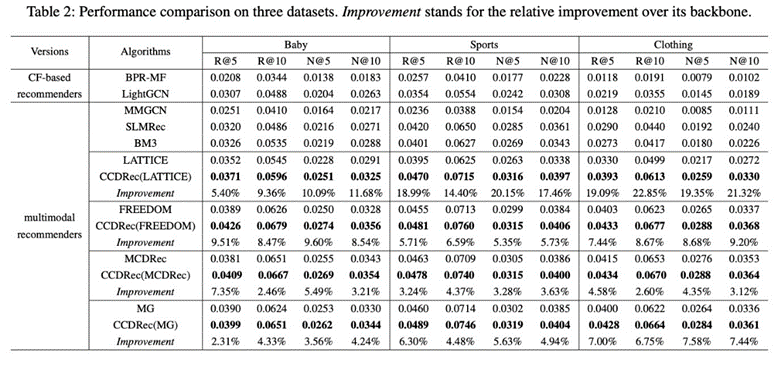
论文概述:多模态推荐(MMRec)旨在整合项目的多模态信息,以解决基于协作的推荐中固有的数据稀疏性问题。传统的多模态推荐方法通常是从多模态图中观察到的用户行为中捕捉结构层面的项目表征,忽略了负面实例对个性化偏好理解的潜在影响。鉴于扩散模型(DMs)出色的生成能力和逐步推理的特点,我们提出了用于多模态推荐的课程条件扩散框架(CCDRec),它精确地挖掘了多模态之间的模态感知分布级相关性,并优雅地将DMs的反向阶段整合到负面采样中,以课程的方式突出最合适的实例。具体来说,CCDRec提出了扩散控制多模态对齐模块(DMA),通过捕捉概率分布空间中多模态之间的细粒度关系,将多模态知识与协作信号对齐。此外,CCDRec还设计了负敏感扩散推断模块(NDI),以逐步合成具有不同难度的负样本池,从而支持后续的知识感知负采样。为了逐步提高训练的复杂性,CCDRec进一步引入了课程式负采样器(CNS),将课程式学习范式与反向阶段相匹配,从而自适应地采样黄金标准负实例以加强优化。结果表明,在三个数据集的所有指标上都明显优于所有基线。这间接证明了多模态扩散增强的项目融合方法和以扩散知识为指导的负采样策略相结合,可以有效利用多模态信息,使模型能够学习用户的细粒度多模态偏好。
3.论文题目:Causal Inference over Visual-Semantic-Aligned Graph for Image Classification(AAAI 2025)
论文作者:Lei Meng, Xiangxian Li, Xiaoshuo Yan*, Haokai Ma, Zhuang Qi, Wei Wu, Xiangxu Meng
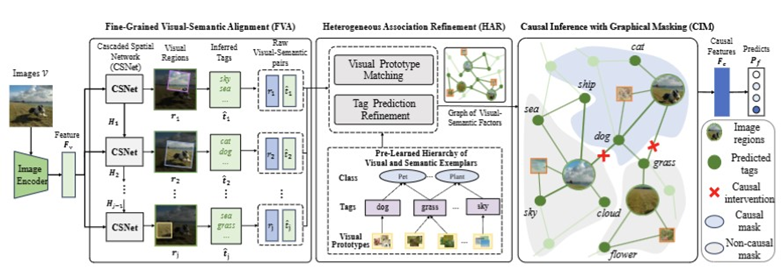
论文概述:当前跨模态对齐方法主要分为显式对齐,隐式对齐和细粒度对齐三类,显式的特征对齐或隐式使用标签作为语义标签等方法难以构建稳定的视觉与语义关联,而细粒度对齐的方法需要在图像区域与标签之间进行对齐,通常还需要额外的检测框,在图像分类的设定下难以使用。为此,我们提出了一种用于图像分类的细粒度视觉-语义关联建模框架VSCNet,其中细粒度视觉语义对齐(FVA)模块采用顺序定位网络动态定位语义密集区域,并同时推断它们对应的文本标记。为了缓解视觉-语义映射中的错误传播,本文提出了一个预先学习的视觉-语义层级结构处理跨模态推断的不确定性,并从视觉模式、标签和类别之间的连接中找到潜在类别。之后,通过异构因果图(CIM)聚合细粒度视觉-语义信息和标签的统一视觉模式,从而学习分类的因果信息,并形成鲁棒的视觉表示。通过在平衡数据集Ingredient-101和长尾数据集NUS-WIDE上的实验结果显示,VSCNet能有效构建图像的视觉-语义关联,并且通过丰富预测信息的融合有效提升分类的效果。
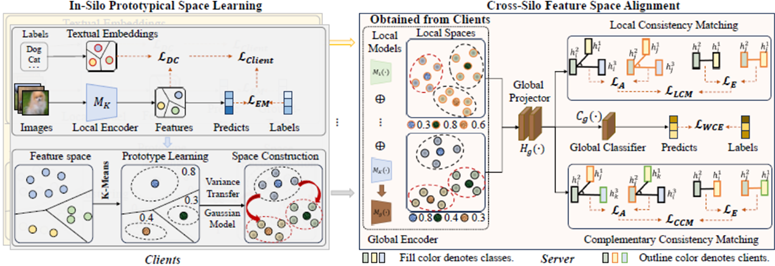
4.论文题目:Cross-Silo Feature Space Alignment for Federated Learning on Clients with Imbalanced Data(AAAI 2025)
论文作者:Zhuang Qi, Lei Meng*, Zhaochuan Li, Han Hu, Xiangxu Meng
论文概述:在联邦学习中,客户端之间的数据不平衡往往导致不同的局部特征空间划分,从而影响全局模型的泛化能力。现有的方法要么采用知识提炼来指导一致的局部训练,要么在聚合之前执行校准局部模型的过程。然而,它们忽略了由不平衡表示学习引起的不适定模型聚合。为了解决这一问题,提出了一种跨源特征空间对齐方法(FedFSA),该方法为客户端学习统一的特征空间,以弥合不一致性。FedFSA由两个模块组成,其中源内原型空间学习(ISPSL)模块使用预定义的文本嵌入正则化局部表示学习,以提高非平衡数据表示的可区分性。随后,引入方差传递方法构建原型空间,辅助校准少数类特征分布,为跨筒仓特征空间对齐(CSFSA)模块提供必要信息。此外,CSFSA模块利用从ISPSL模块学习到的增强特征来学习泛化特征映射函数,并将来自不同源的这些特征对齐到公共空间中,这减轻了不平衡因素所导致的负面影响。在3个数据集上的实验结果表明,FedFSA提高了不平衡数据上不同空间之间的一致性,与现有方法相比具有上级的性能。


会议介绍:AAAI人工智能会议(AAAI Conference on Artificial Intelligence)由人工智能促进协会(Association for the Advancement of Artificial Intelligence, AAAI)举办。会议是人工智能领域历史最悠久、内容覆盖最广的国际顶级会议之一,也是中国计算机学会(CCF)推荐的A类国际学术会议。本届AAAI会议在美国宾夕法尼亚州费城举行,在全球12957篇有效投稿中,3032篇论文被录用,接受率为23.4%,其中Oral论文占比4.6%。会议涵盖了多智能体优化、神经符号推理、不确定性决策、生物多样性计算等前沿方向。

