2025年8月27日–2025年9月1日,第34届国际人工智能联合会议(IJCAI 2025)在广州召开。实验室博士生齐壮参加会议,并汇报展示论文成果。本次会议中,MMRC实验室共有三篇论文被录用,涵盖因果图像表示、异构模态扩散对齐、联邦分布外泛化等前沿议题,充分展现了团队在多媒体数据分析方向上的持续探索与深厚积累。IJCAI作为CCF推荐A类国际会议,汇聚了来自全球人工智能领域的顶尖学者与前沿研究成果,其学术地位和影响力在国际上具有广泛认可。
论文成果。实验室共3篇论文被会议收录,均同时入选oral和poster展示:
成果一:《Empowering Vision Transformers with Multi-Scale Causal Intervention for Long-Tailed Image Classification》
因果推断通过处理类别不平衡引发的偏差,在缓解长尾分类问题中展现出显著潜力。然而,随着主流骨干网络从卷积神经网络(CNNs)向视觉Transformer(ViT)的演变,现有因果模型难以获得预期的性能增益。该成果探究了因果模型在CNNs与ViT架构中的差异性表现,揭示出ViT的全局特征表征特性阻碍了因果方法建立细粒度特征与预测的关联机制,导致具有相似视觉特征的长尾类别难以有效区分。针对此问题,该成果提出基于多尺度因果干预的双阶段因果建模方法(TSCNet)。首先,在分层因果表示学习阶段,该方法通过解耦背景与目标对象,在图像块和特征层面实施后门干预,阻断模型利用类别无关区域进行标签推断的路径,从而增强细粒度因果表征能力。其次,在反事实逻辑偏置校准阶段,通过自适应构建反事实平衡数据分布,优化模型决策边界的训练过程,消除数据分布导致的逻辑输出伪关联。在多个长尾基准数据集上的大量实验表明,所提出的TSCNet能有效消除数据不平衡引发的多重偏差,其性能显著优于现有方法。
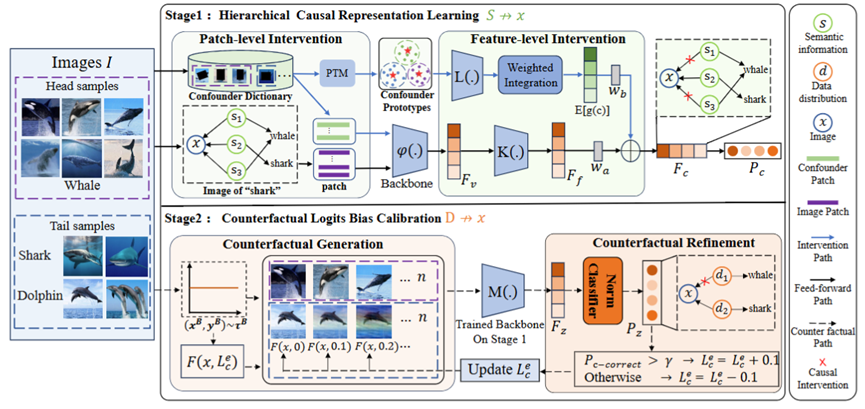
图1.基于多尺度因果干预的双阶段因果建模框架图,有效缓解了数据不平衡带来的性能偏差
本文第一作者为山东大学硕士研究生闫晓硕,指导老师为山东大学孟雷教授(通讯作者)、孟祥旭教授。
成果二:《Semantic-Space-Intervened Diffusive Alignment for Visual Classification》
跨模态对齐能够通过将不同模态的数据(如图像与文本)映射到共享语义空间,有效提升视觉分类性能。然而,现有方法多采用单步投射,将视觉特征映射到文本特征空间,但常因类别分布差异和特征尺度不一致而难以实现理想对齐,从而限制了模型性能的提升。为了解决这个问题,该成果提出了一种语义空间干预的扩散对齐方法(SeDA)。考虑到两种模态的特征在分类中共享相同的类别级信息,SeDA将语义空间作为视觉到文本投射中的桥梁。此外,SeDA还提出了一个双阶段扩散框架,实现两种模态之间的渐进式对齐。具体而言,SeDA首先利用扩散控制语义学习器,通过约束扩散模型的交互特征与视觉特征的类别中心,建模视觉特征的语义空间。随后,在SeDA的后续阶段,扩散控制语义翻译器专注于从语义空间中学习文本特征的分布。同时,渐进式特征交互网络在每一步对齐过程中引入渐进特征交互,逐步将文本信息融合到映射特征中。实验结果表明,SeDA在多个场景下实现了更强的跨模态特征对齐,相比现有方法,表现出显著的性能提升。
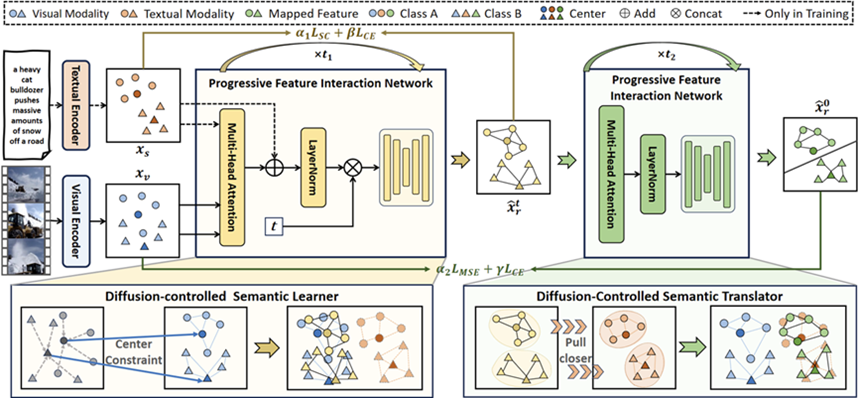
图2.异构模态表征扩散对齐框架图,有效提升跨模态特征对齐效果
本文第一作者为山东大学硕士研究生李子璇,指导老师为山东大学孟雷教授(通讯作者)、孟祥旭教授。此外,哈尔滨工业大学计算机科学与技术学院(威海)晁国清教授对此研究也给予了重要指导与帮助。
成果三:《Federated Deconfounding and Debiasing Learning for Out-of-Distribution Generalization》
联邦学习中的属性偏差通常导致局部模型优化不一致,从而导致性能下降。现有方法通过使用数据增强或知识蒸馏来增加样本多样性,以解决学习不变表示的问题。然而,它们缺乏对推理路径的全面分析,并且来自混杂因素的干扰限制了其性能。针对该问题,该成果提出了联邦去混淆与去偏学习方法(FedDDL)。具体来说,FedDDL基于结构因果模型建模,聚焦数据来源、背景、目标对象和标签等关键变量,在客户端内部实现背景与目标对象的解耦,并通过反事实样本建立背景与类别的关联关系,从而避免模型将背景误判为因果因素。同时,FedDDL仅利用目标对象构建因果原型,以此作为跨源表示对齐的模板,鼓励各客户端模型关注关键目标对象而非背景噪声,推动学习统一的表示空间。实验结果表明,FedDDL在多个基准数据集上显著提升模型性能,平均使9个主流模型的Top-1准确率提高了4.5%。
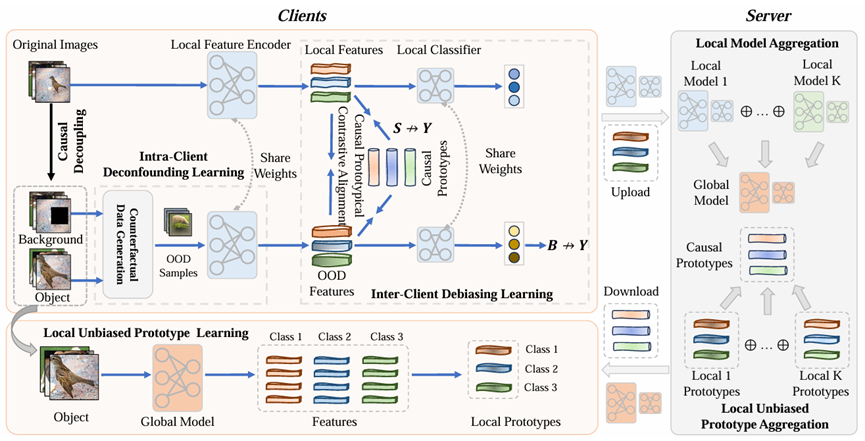
图3.联邦去混淆与去偏学习框架图,能够有效打破背景和标签的虚假关联,并提升了跨源表征对齐效果
本文第一作者为山东大学博士研究生齐壮,指导老师为山东大学孟雷教授(通讯作者)、南洋理工大学计算机与数据科学学院Yu Han副教授、孟祥旭教授。此外,北京理工大学胡涵教授对此研究也给予了重要指导与帮助。

图4.实验室博士生齐壮和杨强教授,Yu Han教授合影留念

图5.实验室博士生齐壮作口头报告

图6.实验室三篇文章海报展示

图7.晚宴活动

图8.实验室博士生齐壮参与大会组织的珠江夜游活动
会议介绍:IJCAI人工智能会议(International Joint Conference on Artificial Intelligence)由国际人工智能联合会(International Joint Conferences on Artificial Intelligence Organization)举办。会议是人工智能领域历史最悠久、内容覆盖最广的国际顶级会议之一,也是中国计算机学会(CCF)推荐的A类国际学术会议。本届IJCAI会议在中国广州和加拿大蒙特利尔举行,在全球5404篇有效投稿中,共有约1043篇论文被录用,接受率为19.3%。会议涵盖了机器学习、计算机视觉、自然语言处理、知识表示与推理等前沿方向。